Concept-Guided Chain-of-Thought Prompting for Pairwise Comparison Scaling of Texts with Large Language Models
Existing text scaling methods require a large corpus, struggle with short texts, or require labeled data. We develop a text scaling method leveraging generative large language models (LLMs), setting texts against the backdrop of information from the near-totality of the web. Our approach, concept-guided chain-of-thought (CGCoT), utilizes expert-crafted prompts to generate a concept-specific breakdown for each text, akin to content analysis guidance. We then pairwise compare breakdowns using an LLM, and aggregate answers into a measure using a probability model. CGCoT transforms pairwise text comparisons from a reasoning problem to a pattern recognition task. We apply this approach to scale affective speech on Twitter, achieving stronger correlations with human judgments than methods like Wordfish. Besides a small pilot dataset to develop CGCoT prompts, our measures require no labeled data and produce predictions competitive with RoBERTa-Large fine-tuned on thousands of human-labeled tweets. We showcase the potential of integrating expertise with LLMs.
This is joint work with Jonathan Nagler, Joshua A. Tucker, and Solomon Messing.
Large Language Models Can Be Used to Estimate the Latent Positions of Politicians
Existing approaches to estimating politicians’ latent positions along specific dimensions often fail when relevant data is limited. We leverage the embedded knowledge in generative large language models (LLMs) to address this challenge and measure lawmakers’ positions along specific political or policy dimensions. We prompt an instruction/dialogue-tuned LLM to pairwise compare lawmakers and then scale the resulting graph using the Bradley-Terry model. We estimate novel measures of U.S. senators’ positions on liberal-conservative ideology, gun control, and abortion. Our liberal-conservative scale, used to validate LLM-driven scaling, strongly correlates with existing measures and offsets interpretive gaps, suggesting LLMs synthesize relevant data from internet and digitized media rather than memorizing existing measures. Our gun control and abortion measures—the first of their kind—differ from the liberal-conservative scale in face-valid ways and predict interest group ratings and legislator votes better than ideology alone. Our findings suggest LLMs hold promise for solving complex social science measurement problems.
This is joint work with Jonathan Nagler, Joshua A. Tucker, and Solomon Messing.
Dictionary-Assisted Supervised Contrastive Learning
Text analysis in the social sciences often involves using specialized dictionaries to reason with abstract concepts, such as perceptions about the economy or abuse on social media. These dictionaries allow researchers to impart domain knowledge and note subtle usages of words relating to a concept(s) of interest. We introduce the dictionary-assisted supervised contrastive learning (DASCL) objective, allowing researchers to leverage specialized dictionaries when fine-tuning pretrained language models. The text is first keyword simplified: a common, fixed token replaces any word in the corpus that appears in the dictionary(ies) relevant to the concept of interest. During fine-tuning, a supervised contrastive objective draws closer the embeddings of the original and keyword-simplified texts of the same class while pushing further apart the embeddings of different classes. The keyword-simplified texts of the same class are more textually similar than their original text counterparts, which additionally draws the embeddings of the same class closer together. Combining DASCL and cross-entropy improves classification performance metrics in few-shot learning settings and social science applications compared to using cross-entropy alone and alternative contrastive and data augmentation methods.
This is joint work with Richard Bonneau, Joshua A. Tucker, and Jonathan Nagler.
MARMOT: A Deep Learning Framework for Constructing Multimodal Representations for Vision-and-Language Tasks
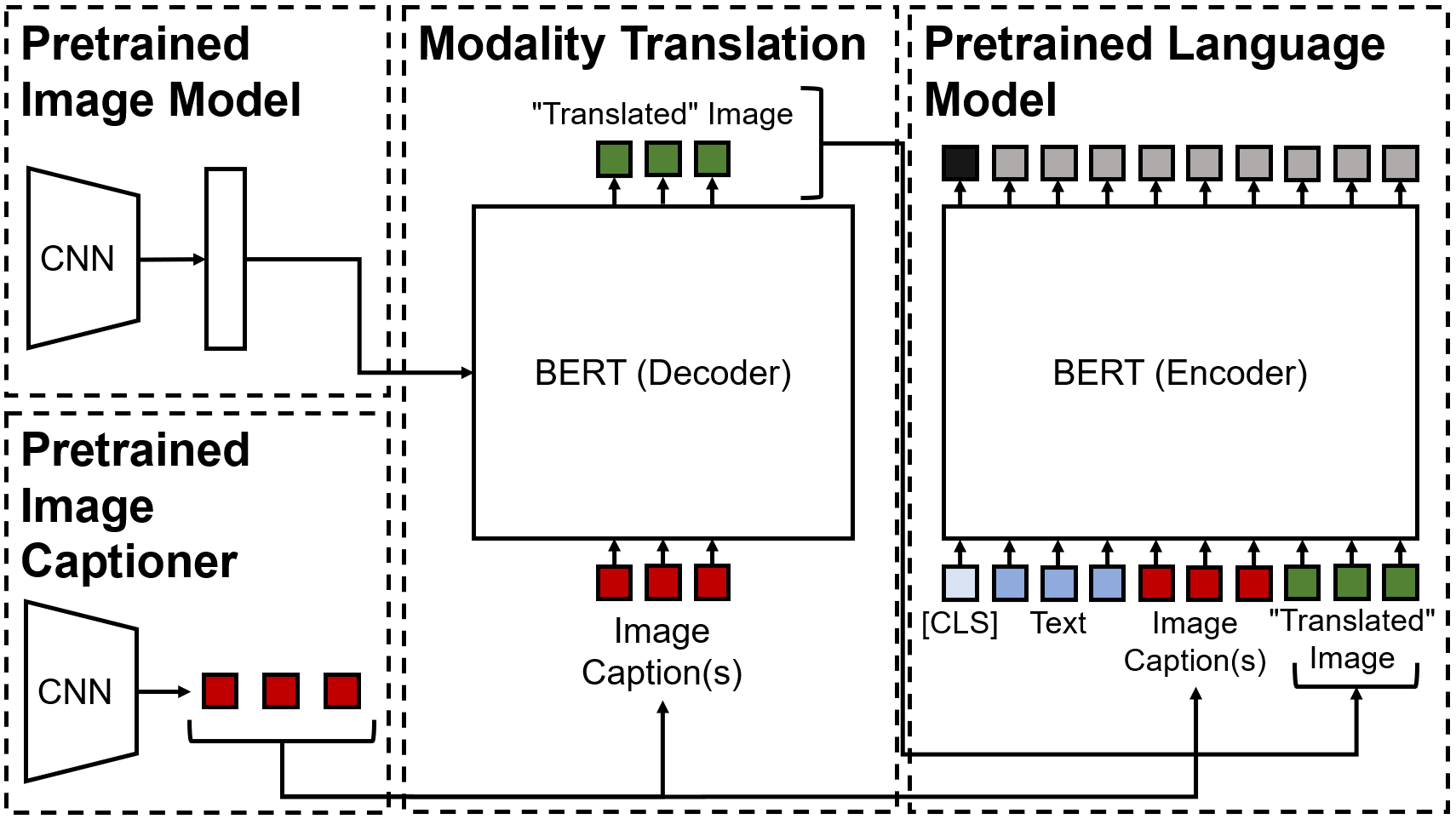
Political activity on social media presents a data-rich window into political behavior, but the vast amount of data means that almost all content analyses of social media require a data labeling step. Most automated machine labeling methods, however, ignore the multimodality of posted content, focusing either on text or images. State-of-the-art vision-and-language models are unusable for most political science research: they require all observations to have both image and text and require computationally expensive pretraining. This paper proposes a novel vision-and-language framework called multimodal representations using modality translation (MARMOT). MARMOT presents two methodological contributions: it can construct representations for observations missing image or text and it replaces the computationally expensive pretraining with modality translation. We use a pretrained BERT transformer decoder to first “translate” the image; then, we jointly input all modalities into a pretrained BERT transformer encoder. This model shows dramatic improvements over existing ensemble classifier methods used in previous political science works on classifying tweets, particularly in multilabel classification problems. It also shows improvements over benchmark state-of-the-art models on image-text problems.
This is joint work with Walter Mebane.
Partisan Associations from Word Embeddings of Twitter Users’ Bios
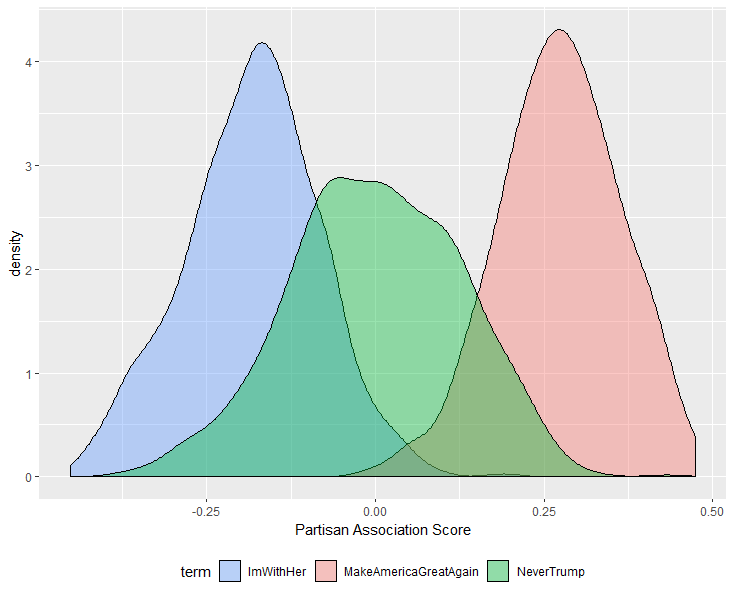
One of the principal problems that faces political research of social media is the lack of measures of the social media users’ attributes that political scientists often care about. Most notably, users’ partisanships are not well-defined for most users. This project proposes using Twitter user bios to measure partisan associations. The method is simple and intuitive: we map user bios to document embeddings using doc2vec and we map individual words to word embeddings using word2vec. We then take the cosine similarity between these document embeddings and specific partisan subspaces defined using partisan keywords that refer to presidential campaigns, candidates, parties, and slogans to calculate partisan associations. The idea of this approach is to learn the non-partisan words that are in the contextual neighborhoods of explicitly partisan words. Even if someone does not explicitly use partisan expressions in their bio, he or she may describe themselves with words that the descriptions that feature explicit partisan expressions tend to contain. This idea resonates with research that studies the associations between partisan sentiments and seemingly non-partisan identities, activities, hobbies, spending habits, and interests. Our project shows that these measures capture partisan engagement and sentiment in intuitive ways, such as which partisan users they retweet, favorite, follow, and what hashtags they use.
This is joint work with Walter Mebane, Logan Woods, Joseph Klaver, and Preston Due.